

You have probably heard the term “iterator” in reference to DAX. An iterator is any function that performs its operations row by row. Using an iterator is required for any calculation that will be wrong if it is not calculated row by row. In the figure below, you can see a simple example of a calculation that requires an iterator.
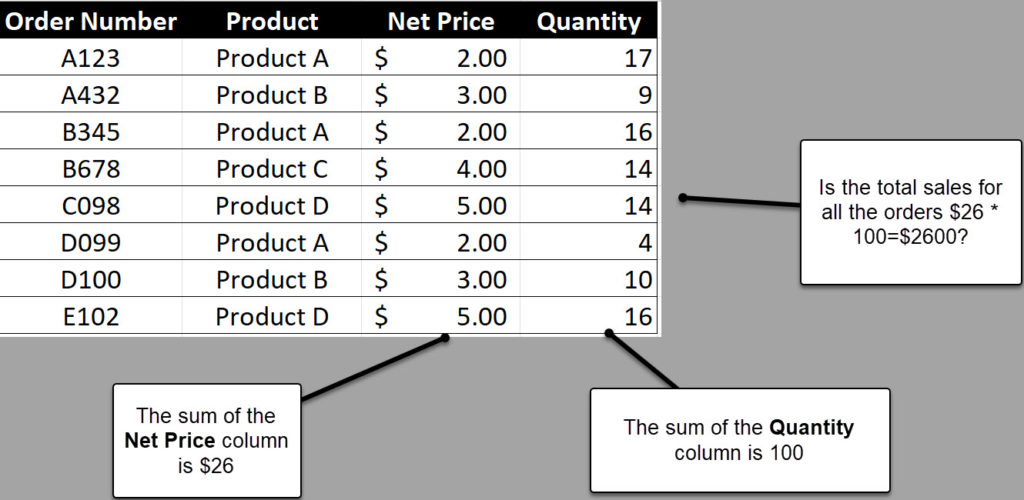
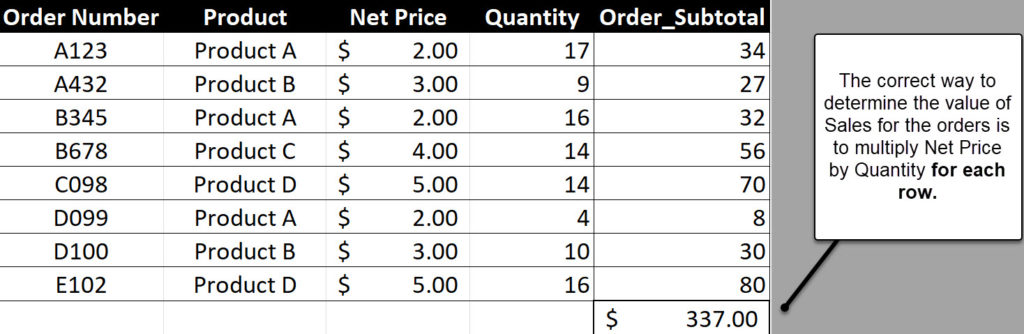
If the Order_Subtotal column were created in DAX, it would look like this:
Order_Subtotal=SUMX(‘Orders’,’Orders'[Net Price] * ‘Orders’ [Quantity])
SUMX is an iterator function; you can tell because it has an X at the end of it. Guess what other function is an iterator (even though it doesn’t have an X in the name): FILTER. Any function that must go through a table row by row to perform its action is an iterator.
Iterators are resource hogs, because they have to look at each row of the table they are scanning. If the table only has a couple thousand rows, it’s not a big concern. If a table has millions of rows, you do need to be aware of the requirements of an iterator. In a previous blog post, I said you can use a FILTER function inside of another iterator function (or indeed any function that requires a table as an argument). Here’s the DAX expression in question:
Sales>10Kv2=
SUMX(
FILTER(‘Order Header’, ‘Order Header'[Total Due]>10000),
‘Order Header'[Total Due])
But let’s look closely at what is going to happen. It is first going to evaluate the FILTER expression by iterating through the ‘Order Header‘ table and return only the rows that have a Total Due greater than $10,000. The resulting table is then passed to the SUMX operation, which will then proceed to iterate through the table again, adding up the Total Due column.
Again, if the ‘Order Header‘ table has just a small number of rows (relatively speaking), the double iteration is not an issue. But if there are millions of rows in the table, and millions of rows even after the table is winnowed by the FILTER expression, you may want to re-think this approach.